meta分析的统计学问题
发布于:2013-10-18 17:15
“meta”来源于希腊语,意为“之后的,更综合的,二次的”。meta分析是指对关注同一科学问题的不同研究的结果进行定量综合的统计方法。通常,研究的样本量大小直接影响效应估计的精确度。而效应估计的精确度高低,则直接反映为其可信区间的宽窄。因而,样本量越小的研究,其效应估计的精确度越低,相应的可信区间越宽,就越可能出现统计学上不确定的结果;样本量越大的研究,其效应估计的精确度越高,相应的可信区间就越窄,越容易出现统计学上显著的结果。例如,2项关注降压药效果的、以血压为结局的研究分别获得了-4 mmHg (-7,3)和-4 mmHg (-7,-2)的研究结果。前者的可信区间较宽,其效果在统计学上是不确定的(既可能使血压降低最多7mmHg,又可能使高血压升高最多3 mmHg,还可能对血压没有任何效果);后者则发现了统计学上显著的降压效果。

meta分析是否适用,与异质性的大小密切相关。通俗地说,异质性(heterogeneity)就纳入系统综述中的原始研究之间的差异。根据其来源的不同,可分为临床异质性、方法学异质性和统计学异质性。临床异质性是指原始研究在研究对象、干预措施、对照或结局等临床特征上的差异,方法学异质性是指原始研究在研究设计、研究质量上的差异,由临床异质性和(或)方法学异质性所导致的原始研究效应估计上的差异,称为统计学异质性。
异质性检验可用于检查原始研究的结果是否具有一致性或可合并性。由于meta分析的样本量是纳入研究的数量,在纳入研究数量较少时把握度较低,因而判断异质性检验显著性的P界值通常为0.10(不是一般统计学检验的0.05)。当P≤0.10时,则认为原始研究的结果存在统计学上显著的差异,即存在异质性。另外,也可以通过异质性检验提供的I2对异质性的大小进行定量判断(例如当I2>50%时,可认为存在统计学上显著的异质性)。一般情况下,如果存在严重的异质性(特别是临床异质性),则不适合直接使用meta分析进行结果合并。
meta分析具有2种模型,即固定效应模型和随机效应模型。在固定效应模型里,所有研究估计的是同一个干预效应,研究结果之间的差异完全来源于机会,即没有统计学异质性。在随机效应模型里,所有研究估计的不同的、但服从某个对称分布的多个干预效应。对称分布的中心反映了这些效应的平均值。研究结果之间的差异不仅来源于机会,也来源于干预效应的不同。
当meta分析不适用时,可以通过叙述性合并(narrative synthesis)对原始研究的结果进行定性合并,即通过表格对合格研究的研究特征(如研究设计、研究对象、研究结局、研究质量等)与研究结果进行结构化的比较和总结,定性评价研究结果在不同研究特征上是否相似(即研究结果是否与某些研究特征有关)。
因此,是否适合开展meta分析,主要取决于对异质性的评价(图1)。对于纳入的合格研究,首先应评价是否存在严重的临床异质性,如果存在则应根据临床异质性的来源进行亚组meta分析或叙述性合并;如不存在严重的临床异质性,则可通过异质性检验定量评价异质性,并根据统计学检验的显著性选择固定效应模型或随机效应模型进行meta分析。另外,不论是否存在统计学上显著的异质性,都鼓励通过亚组分析或meta回归对异质性的来源进行探索,从而有利于获得对临床决策具有重要意义的线索(例如治疗在某些特征的患者中有效,而其他患者中无效)。

常见的结局数据包括连续数据和分类数据两种类型。对于连续数据,原始研究通常使用均数差(mean difference,MD)作为结局指标,在meta分析中则通常使用均差(meandifference,MD)或标准化均差(standardized mean difference,SMD),后者主要适用于对同一结局指标采用不同的测量单位的情形(如不同量表)。对于分类数据,原始研究通常使用相对危险度(relative risk,RR)或比值比(odds ratio,OR)。具体分析过程可以使用Revman、meta-Analyst、metaTest等软件进行(以Revman使用较为广泛)。
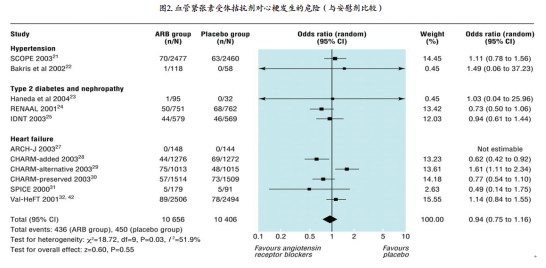
meta分析的结果主要以森林图的形式呈现。以McDonald MA等2005年在BMJ杂志发表的系统综述中的森林图为例,来说明如何阅读meta分析的结果(图2)。该系统综述通过meta分析关注血管紧张素受体拮抗剂对心梗发生的危险。每一行代表一项原始研究的信息,包括作者与发表时间、治疗组发生心梗的例数与总例数、安慰剂组发生心梗的例数与总例数、原始研究的效应估计与95%可信区间以及meta分析中赋予该项研究的权重值。线段的两端分别代表95%可信区间的上、下限,正方形的中心代表效应估计值,其面积大小代表研究被赋予的权重多少。通过meta分析产生的结果用菱形(钻石形)表示,其跨越无效线,则提示未发现治疗组与安慰剂组之间的显著差异。图形的下部提供了异质性检验的结果,P=0.03提示存在统计学异质性,应采用随机效应模型进行meta分析。
的散点图。样本量小或精确度低的研究结果通常分散在图形底部很宽的范围内,而随样本量增大,精确度提高,研究结果则集中在图形上部一个较窄的范围内,从而形成一个对称的倒漏斗形状。因此,通过检查漏斗图的对称性,可以检验是否存在发表偏倚。如果图形呈现明显的不对称,表明偏倚可能存在。
有时,meta分析会进行敏感性分析,即采用两种或多种不同方法进行meta分析,比较这两个或多个结果是否相同的过程,其目的检查结果的稳定性。例如由于信息缺失无法判断某项研究是否应纳入,此时可将该项研究在纳入和不纳入的情况下分别进行meta分析并比较结果是否相同。此外,敏感性分析还可用于检查低质量研究、非英文文献、对原始研究进行的调整分析或估算是否影响了结果的稳定性。
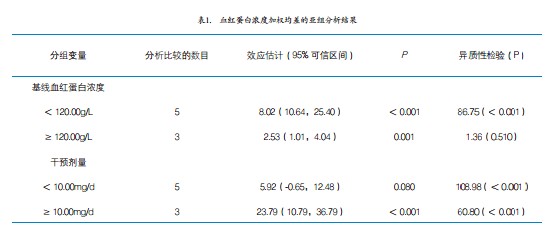
通过对异质性来源的调查,有助于获得可能具有重要的临床意义的发现,以及为新的研究提供线索。常用的调查异质性来源的方法包括亚组分析和meta回归。在选择特征变量(分组变量)时应有其他生物学证据的支持,并应在分析前就确定要调查的特征变量,事后分析容易出现假阳性。表1提供了一个亚组分析的实例。在该项meta分析中,我们关注了EDTA螯合铁改善铁缺乏人群血红蛋白的效果。并选择基线血红蛋白浓度和干预剂量2个特征变量进行了亚组分析,结果发现基线血红蛋白浓度越低,治疗效应越大。
来源于:《医心评论》第66期
医心微信 >


 京公网安备 11010102002968号
京公网安备 11010102002968号