医学统计学的逻辑基础与报道准则
发布于:2013-10-18 16:55
从本质上看,一般进行医学科学研究必须采用两种方法,其一是专业方法,其二是统计方法。前者保证课题研究的创新性,后者保证研究的科学性。医学统计方法是所有从事医学研究的共同方法。弄清其内在逻辑含义,则有助于我们正确使用与报道。这对稿件的快速被接纳及知识传播无疑具有重大意义。
1. 由样本到总体与不完全归纳
统计学的核心问题是研究总体与样本之间的关系。
总体(Population)是我们研究的全部对象。总体又分为无限总体和有限总体。例如,我们要研究新生儿体重,因为新生儿是无止境的,所以这一总体可以设想是无限的。如果要调查一所学校今年新生的身高,这一总体则是有限的。生物统计学所遇到的总体多数都是无限总体。构成总体的每个成员称为个体。由于总体的无限性或总体很大,为了达到对总体的认识,又无法穷尽总体的所有个体,为此采取了科学“抽样”得到样本,通过对样本的研究推断其总体。其实质是采用的不完全归纳法。
样本是总体的部分。样本内个体数目称为样本含量。如何确定样本的含量属于科学归纳问题。
2.1 对照原则与“求因果五法”的差异法
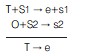
 –
–
所以,A情况是a现象的原因(或结果)
从以上可以看出:生物实验是从处理因素→处理因素引起的效应;差异法是从效应(现象)→引起效应的因素(情况),它们的思维方式和操作的出发点相反,但它们都是寻求原因效果的一一对应关系。从公式可以得出两者的本质是一样的。可以说对照是求因果关系五法的差异法在医学实验中的具体应用。它是一种探求事物内在联系的科学方法。
重复(Replication)就是将一基本实验重做一次或几次。例如,测定不同年龄组正常人的血红蛋白含量的实验,在每一年龄组内测定一人,即为一基本实验,若将这一基本实验重做5次,即每一年龄组抽取5人测血红蛋白含量,则称该实验有5次重复。重复有三个重要意义:(1)因为只有重复,才能得到实验误差的估计。根据误差的估计值,才能判断处理之间的差异是否存在统计学上的显著性。(2)设置重复,可以更精确地估计处理效应。例如,比较两种不同药物的疗效,每一种药物只由一人服用。服用A药的人10天痊愈,服用B药的人12天痊愈。这时我们无法正确判断药效有无差异。两种药物之间的差异可能是药效不同,也可能是由于实验误差造成的。若以上结果是n次重复的平均值,由于平均数的方差只是样本方差的1/n(sx2=s2/n),当n足够大时,A和B之间的差异,就有理由认为是不同药物的效应。(3)重复是扩大一个实验的推断范围的方法。我们不能根据一个或几个人的某项检测值而推断总体人群这项值的范围。只有通过选择适宜的变动相当多的n个人检测值,即重复n次实验后,才能从样本达到对总体的推断。因此,重复是对归纳事物研究量的保证,即所归纳的事物要达到一定的数量。达不到一定数量的事物的归纳是不可靠的归纳。重复保证了研究过程中研究对象或次数的量。
和Cox说过:“随机化多少有点像保险,它是一种对付也许会也许不会发生的扰乱的防患未然的措施,这种扰乱即使发生,也是可能严重可能并不严重”。对实验做适当的随机化从效应上讲还可以平均掉可能存在的外来因素的影响。如在前面药效实验中,假设药效受年龄影响。若服A药的都较年轻,服B药的都较年老,这时药效与年龄效应混杂,降低了实验结果的可靠性。经过随机化,每一药物组中均有不同年龄的个体,这样就可以防止不同处理之间比较时可能产生的偏倚。总之,随机化原则保证了研究过程中质的规定性。
概率(Probability)是事物发生的度量。事件如属常有,它的发生概率是大的;事件如属不常有,它的发生概率是小的。大多数人都以一种或另一种方式使用过整个范围的概率。如果有人说:“这次火警可能是粗心大意之故”,他对于原因何在根本还没有确定;如果他说:“这次火警几乎肯定是粗心大意之故”,他对于原因的感觉就很强烈了。统计学中把此类形容性的但不确定的诸如“可能、几乎肯定”等字眼代以处在0~1之间的数字;精确地指示出一桩事件可能到怎样或者不可能到怎样。统计学方法被用来从局部推断整体,即从样本推断总体。显然在资料不完全的情况下,我们不能期望每一推断都是正确的,机遇起了一部分的作用,那些因果关系很明确的定律并不适用。在这种情况下,我们就必须借助概率这个概念来描述对某一推断程度的量度或者借助概率和假设检验达到统计推断的目的。从某种意义上说概率是统计归纳推理最基本的概念,离开了概率,统计归纳推理就失去度量的工具。
我们根据统计的原理,利用一般数学方法获取了关于样本的数据后,如何通过样本去推断总体呢?由样本推断总体是以各种样本统计量的抽样分布为基础的。对总体的推断可以通过两条途径进行。其一是统计假设检验(Statisticaltest of hypothesis);其二是总体参量估计(Estimation ofpopulation parameter)。这里主要讨论假设检验与统计推断。如试验某种减肥药是否有效,可通过样本中用药前、后体重的差值作出推断,并对该药是否可推广作出决策。在作假设检验时,首先要有个假设H0:该药无减肥作用,其对立的假设H1则是该药有减肥作用;然后用配对计量资料t检验(或其他方法)来验证假设;最后再作出拒绝或不拒绝H0的结论。这里的“建立假设——验证假设——作出结论”贯穿着反证法(Reduction ad absurdum)的逻辑推理过程。
(1)假设是对于总体特征的表述。上例推论的总体是假想的,包括所有使用该药的受试者用药前后的体重差值,其均数为μ,因而可写成H0:μ=0,H1:μ>0。(2)H0是从反证法的思想提出的。本例最初的问题是“该药是否能减轻肥胖者的体重?”而这里提出的H0是“该药无减肥作用”,称无效假设,意图是提出根据以否定它,即回答:“是的,该药能减轻体重。”故H0亦称解消假设。H1是和H0相联系而对立的。(3)H0与H1不是平列的。H0是验证的主题,只有在H0被拒绝的情况下才接受H1,故H0称为备择假设。(4)H0和H1的具体表述随资料性质、分析目的和检验方法而异。
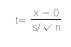 式中 x为样本体重差值的均数,s为差值的标准差,n为样本含量,0来自H0∶μ=0。因此,上述t 的抽样分布可视为在H0成立条件下统计量t 的概率。如果这里不用H0,那也就无法获得t 的分布。(3)推理的基本思想是反证法。意思是如果在某一统计量的概率分布中,抽得现有样本统计量的概率P很小,我们就怀疑样本数据与所设H0有矛盾,而这种矛盾不宜用抽样误差来解释,故拒绝H0;相反,若抽得现有样本统计量的概率P并不小,也就是样本数据与所设H0虽不一致,但仍可用抽样误差来解释,故我们就没有理由拒绝这个H0 。(4)确定P值的大小应该事先规定一个标准,这个标准称为检验的含量,即检验水准或显著水准α。
式中 x为样本体重差值的均数,s为差值的标准差,n为样本含量,0来自H0∶μ=0。因此,上述t 的抽样分布可视为在H0成立条件下统计量t 的概率。如果这里不用H0,那也就无法获得t 的分布。(3)推理的基本思想是反证法。意思是如果在某一统计量的概率分布中,抽得现有样本统计量的概率P很小,我们就怀疑样本数据与所设H0有矛盾,而这种矛盾不宜用抽样误差来解释,故拒绝H0;相反,若抽得现有样本统计量的概率P并不小,也就是样本数据与所设H0虽不一致,但仍可用抽样误差来解释,故我们就没有理由拒绝这个H0 。(4)确定P值的大小应该事先规定一个标准,这个标准称为检验的含量,即检验水准或显著水准α。
(1)若P≤α,则拒绝H0,这就是“有显著性”的同义语。按反证法的逻辑推理必须导致接受H1。如上例可以认为该药减肥有效,可以推广。
(2)若P>α,则不拒绝H0, 就是“无显著性”的同义语。按反证法的逻辑推理,不拒绝H0,却未必蕴藏着H0的真实性。而从决策论的观点看,只好接受H0,或者说暂时接受它。如上例,可认为该药无效,不予推广。这点类似临床上常说的:“根据现有检验,未发现阳性结果,只好作无病处理 。”;或者说:“阴性待诊”。
(3)上述两种结论不是绝对的肯定或否定,都有发生错误的可能性,因而是概率性的。在医学科学研究中经常用到假设检验,正确理解其基本涵义和逻辑推理将有助于正确应用。
x±t0.05,νsx[样本均数±(α=0.05,ν=n-1时的t 界值)×标准差]:是在μ与σ未知的情况下,估计总体均数可能在什么范围内,称为95%可信区间。理论上作100次估计,求得100个区间,其中有95个区间将包含总体均数在内。这是从个性到共性,在思维方法上属归纳推理形式。
总之,统计方法是充满辩证法的数学方法,对其辩证表达、推理与运算的理解,无疑会有助于正确运用。
二、医学统计学的报道准则
15. 规定统计术语、缩写及常用符号。
(参考文献略)
来源于:《医心评论》第66期
医心微信 >


 京公网安备 11010102002968号
京公网安备 11010102002968号